A Guide to Feature Flags
Table of Contents:
What is a Feature Flag?
How Do Feature Flags Work?
The Mechanics of Feature Flags
Types of feature flags
Release Flags
Experiment Flags
Kill Switches
Operational Flags
Permission Toggles
De-risking Releases
Use Cases of Feature Flags
Rollback
Progressive Rollouts
A/B/n Testing
Kill Switches
Trunk-based development
In 2014 I was working as a software developer at FINN.no, Noway’s largest online marketplace. Getting new features into production was a pain, so, as a developer, I looked around and wondered if I could write some code to make it easier. My initial goal was to protect features under development, allowing our team to transition to trunk-based development – a practice recommended according to the State of DevOps Report.
Already in 2014, we embraced agility with an automated delivery pipeline. Deploying bug fixes was a breeze, but frequent feature releases? Not so much. Building features takes time, and waiting weeks for production testing felt wasteful.
We used feature branches, a common approach, to isolate unfinished features. However, this created a tangled web of problems:
- Limited Feedback: Getting stakeholder input required manually deploying test environments for each branch, a cumbersome process.
- Merge Mayhem: Conflicts became a constant headache, delaying progress.
- Production Mystery: Would our change actually work in production with production data? Were there any edge-cases we had not considered?
Frustrated by the slow pace, and the additional complexity of feature branches, I explored ways to streamline it through code.
As CTO of Unleash, the leading open-source feature flag solution, I’ve learned a lot about feature flags in the last 10 years, and this blog aims to share some of what I’ve learned. Software is complex, and not every suggestion here will make sense for every customer or use case. But in general, if you follow these best practices, you’ll ship software a lot faster and have a lot more fun doing it.
What is a Feature Flag?
Releasing software is not for the faint of heart. Every release is a potential minefield of merge conflicts, undiscovered bugs, unintended consequences, and CI/CD pipeline explosions. Feature flags act as a safety net. These aren’t just fancy gadgets or trendy buzzwords; they are an essential tool that can significantly reduce the risk and stress of deploying new features.
At its core, a feature flag is a mechanism that allows developers to turn certain features or functionality on or off without redeploying the entire application.
Ben Nadel, co-founder and CTO of InVision, in his talk Feature Flags Change Everything About Product Development, says that feature flags are “just” if statements. If that sounds underwhelming, he also goes on to say that just like he can’t imagine building products without logs or metrics, he can’t imagine building without feature flags. They are that critical, for reasons we will look into below.

Source: https://www.bennadel.com/resources/uploads/2021/dev-week-2021-feature-flags/007.png
You can think of a feature flag as a remote control for your app’s features, enabling you to manage them in real time, in the live environment, with just the flip of a switch. It’s run-time control over what your users see when they login. And it’s really powerful.

Why are feature flags so important to software development? Because they allow you to decouple the deployment of code from the release of features. In the traditional deployment process, pushing new code to production affects all users immediately. This is where feature flags shine—they let you discreetly integrate new code into the production environment and activate it only when you’re ready.
This is particularly valuable for engineers in large enterprises. Feature flags offer granular control over who sees what and when, allowing for phased rollouts, targeted testing, and quick reversals if things go wrong. This isn’t just about reducing risk; it’s about empowering your team to innovate confidently, knowing they can introduce changes without causing unnecessary disruption.
In the grand scheme of things, while CI/CD processes are vital for code deployment, feature flags offer additional flexibility and safety for turning on actual features. They enable teams to test in production, tailor experiences for different user segments, and ultimately, make more informed decisions about when and how new features are introduced.
How Do Feature Flags Work?
Feature flags have enabled development teams to manage features in a dynamic, flexible, and controlled manner. But like any tool, you need to use them the right way. You don’t want to build a spaceship out of bricks.

https://imgs.xkcd.com/comics/the_wrong_stuff.png
Implementation in the Development Process
Feature flags are integrated into the software development lifecycle, allowing developers to introduce code conditionality. This conditionality determines whether specific blocks of code execute, enabling or disabling features without requiring code deployments. The code for the feature is already deployed. A feature flag controls where it executes at run-time.
At its most basic, a feature flag is implemented as a conditional statement in the source code. This conditional hinges on a flag value, typically retrieved from a configuration file or a feature management platform, to decide whether a particular code path should be executed.
The Mechanics of Feature Flags
Conditional Statements: Conditional statements embedded within the application’s code are at the heart of feature flag implementation. These conditionals evaluate whether a feature flag is turned on or off and then dictate the execution flow accordingly.
Targeting Rules: The behavior of feature flags is governed by a set of targeting rules, which can be as simple as boolean flags or as complex as context-aware parameters (e.g., rollout of this feature to users who are accessing the applications from Singapore). These rules can be adjusted in real-time, allowing development and product teams to modify feature behavior without touching the codebase again.
Run-time Control: When the application runs, these conditional checks are evaluated in real-time, determining which features are active or inactive. This real-time evaluation enables quick responses to operational needs, user feedback, or other external factors.
An Example of How Feature Flags Work
Consider a scenario where a software team is working on a new user profile page but is not ready to release it to all users. They can implement a feature flag to control its visibility:
if unleash.isEnabled(‘newProfilePage’) {
showNewProfilePage();
} else {
showOldProfilePage();
}
In this example, “newProfilePage” acts as a feature flag. When the flag is set to true, users are directed to the new profile page; when false, they see the existing page. This flag can be controlled externally, allowing product managers, developers, or operations teams to enable or disable the new profile page at runtime, without deploying code changes.
By using feature flags in this manner, teams can seamlessly integrate new features into their applications, test them in production, gather user feedback, and make informed decisions about their release, all while maintaining a stable and reliable user experience. It also enables product teams to release features to their users gradually.
Types of feature flags
Now you understand why feature flags are critical instruments in the modern software engineering toolkit. Understanding the different types of feature flags, their purposes, and ideal feature flag lifespans is essential for leveraging their benefits to the maximum.
When we work with enterprises, we use this breakdown which was heavily influenced by Pete Hodgson’s taxonomy of feature flag types.
| Feature toggle type | Used to … | Expected lifetime |
| Release | Enable trunk-based development for teams practicing Continuous Delivery. | 40 days |
| Experiment | Perform multivariate or A/B testing. | 40 days |
| Operational | Control operational aspects of the system’s behavior. | 7 days |
| Kill switch | Gracefully degrade system functionality. You can read about kill switch best practices on our blog. | Permanent |
| Permission | Change the features or product experience that certain users receive. | Permanent |
Pete laid out the types in a graph like so, and we have separated out Kill Switches from Operational flags for reasons I will get into below.

Inspired and extended from Pete Hodgson’s taxonomy of feature flag types https://martinfowler.com/articles/feature-toggles.html
Here are more details on those different types of flags, their benefits, and their expected lifetime. Understanding these differences is important because feature flags are technical debt. Debt can be a good thing, but it can also get away from you.
Release Flags
Purpose
Release flags are employed to manage the deployment of new or incomplete features, enabling teams to integrate code into the mainline without immediately exposing it to all users. This practice supports continuous integration and delivery by always keeping the main branch deployable.
Benefits
The primary benefit of release flags is risk mitigation. They allow for incremental development and testing of features in production without impacting the entire user base, thereby enhancing stability and reliability.
Lifespan
While release flags are invaluable, they should be short-lived to prevent codebase complexity and technical debt accumulation. Once the feature is complete and tested, the flag should be removed to streamline the code. Ideally, release flags should not remain active beyond a few weeks to a few months, depending on the feature’s scope.
Experiment Flags
Purpose
Experiment flags facilitate A/B and multivariate testing, enabling teams to evaluate different user experiences and determine the most effective iterations. They segment users into cohorts, providing data-driven user preferences and behavior insights.
Benefits
These flags empower teams to make informed, evidence-based decisions on feature implementation, optimizing the user experience based on actual usage data and feedback, thereby maximizing product value and user satisfaction.
Lifespan
Experiment flags are dynamic and transient. Their lifespan is inherently limited to the duration of the experiment—enough to gather significant data but not so long as to risk polluting the findings with unrelated changes or prolonging the exposure of potentially suboptimal features. Typically, they are active for a few days to a few weeks.
Kill Switches
Purpose
Kill switches serve as emergency levers, allowing teams to quickly disable certain functionalities or features in response to critical issues like severe performance degradations or security vulnerabilities. Unlike other operational flags, kill switches are designed for rapid, decisive action in crisis situations. They often impact user-facing features to preserve overall system stability or security.
Benefits
The advantage of kill switches is their ability to provide immediate remediation in the face of unexpected, critical incidents. By preemptively implementing these switches, teams can ensure they have a fail-safe mechanism to maintain control over the system’s operational integrity, even under adverse conditions.
Lifespan
Contrary to the short-lived nature of most feature flags, kill switches are inherently long-term or even permanent tools within a system’s architecture. Their enduring presence allows for ongoing protection against unforeseen critical events. However, these switches must be regularly reviewed and tested to ensure they remain functional and relevant, adapting to the evolving system and operational requirements.
Operational Flags
Purpose
Sometimes Kill switches and other types of ops flags are combined when discussing feature flag types. However, I like to break out Kill switches from generalized Operational Flags because they have different lifecycles. Ops flags should be employed to manage a system’s technical aspects that do not directly influence user-visible features but are crucial for the application’s underlying stability and performance. An example includes transitioning from one library version to another, where operational flags can toggle between the old and new implementations to ensure the update does not adversely affect the system.
Benefits
The primary benefit of these operational flags is their capacity to facilitate seamless transitions between technical implementations with minimal risk. By enabling real-time switching between different operational states or configurations, these flags allow for thorough validation of changes in a live environment without disrupting the user experience.
Lifespan
Operational flags of this nature are intended to be short-lived, existing only long enough to confirm that a change, such as a library update, is stable and does not introduce regressions. Once the new state is validated, the flag should be promptly retired to avoid accumulating technical debt. The lifespan for such flags typically ranges from a few days to a couple of weeks, depending on the complexity of the change and the confidence level achieved through monitoring and testing. It can be tempting to use Ops Flags as a solution for long-term configuration management, but this would be a mistake. Configuration management should be handled long term using version control, not feature flags. Read more on why feature flags should be short lived here.
Permission Toggles
Purpose
Permissioning toggles control feature access based on user roles or entitlements, allowing for features to be selectively enabled for different user segments, such as internal, beta, or premium users.
Benefits
These toggles facilitate phased feature exposure and can help garner early feedback from select user groups or deliver enhanced functionality to premium users, thus driving engagement and value differentiation.
Lifespan
The lifespan of permission toggles can vary significantly. While they might be permanent for certain features exclusive to specific user tiers, it’s crucial to distinguish these from short-lived feature flags. For features eventually intended for broader release, the toggles should be transitional, aligning with broader access strategies and product evolution. For example, you might roll out a new beta feature to enterprise users using a feature flag. But once it goes GA, you should use a proper permission service to enable/disable access to the feature.
Use Cases of Feature Flags
You might think that at this point, every development problem is a nail, and feature flags are the hammer. That is not the case. Feature flags are great for a lot, but not for everything. Before discussing some common use cases for feature flags, let me talk about one anti-pattern.
Feature flags != Configuration management.
Why? Feature flags are technical debt and you want to pay down your debts over time. It’s hard to argue that environmental variables and other configurations like library versions are technical debt that need to be paid down. Yes, they need to be maintained, but remember, with rare exceptions, feature flags are supposed to be short-lived. The fact that your application runs out of us-east-1a isn’t really something you want to think about sunsetting. Keep your configuration in version control where it belongs. And use feature flags for things like:
De-risking Releases
In the context of de-risking releases, feature flags act as a safety net, incrementally introducing new functionalities to the user base. Instead of rolling out a feature to all users simultaneously, teams can activate it for a select group and monitor its performance and reception. For instance, an application’s newly developed chat feature can initially be released to just 10% of the user base, with the team observing usage patterns and feedback for any potential issues before a wider release. In some extreme examples, like at Invision mentioned above, feature flags let dev teams deploy to production with no automated tests because rolling back features that cause issues becomes so trivial. Which leads us to…
Rollback
Even if you continue to use automated tests for things you know can go wrong, feature flags make it easy to rollback when unexpected issues occur. By simply toggling the feature off, developers can mitigate issues without impacting the overall application, avoiding the complexities and risks of a full-scale code rollback. Imagine a scenario where a new image compression algorithm is causing longer page load times; a feature flag can quickly disable this algorithm, reverting to the previous state while the issue is investigated.
Even if you have a next-level CI/CD setup, you don’t want to roll back features using it. Charity Majors has a great blog on why not.
Tl;dr rolling back a single line of code can take just as long as hundreds or thousands of lines. CICD is a great way to get code into and out of prod. Use feature flags for functionality.

Progressive Rollouts
Progressive rollouts of features (where new functionality is gradually exposed to a broader audience based on successful interim outcomes) are much better than all-or-nothing releases. This phased approach allows for collecting valuable user feedback and performance data at each stage, enabling fine-tuning or course corrections as needed. For example, a cloud storage service might introduce a new file-sharing interface to a small percentage of users initially, expanding the rollout as confidence in the feature’s stability and usability grows. The alternative is super long testing cycles that any developer will tell you will still miss some bugs. It is much better to ship code quickly and start with a small audience that you can validate before rolling out more broadly.
A/B/n Testing
Using feature flags for A/B/n testing empowers teams to experiment with different implementations of a feature to determine which one resonates best with users or meets predefined success criteria. By directing different user segments to experience variant features, data can be gathered to inform which version effectively achieves the desired objectives. An online bookstore, for instance, could test two different landing page designs to identify which one yields a higher engagement rate or increases sales, thereby making data-driven decisions to enhance user experience and business outcomes.
Kill Switches
Kill switches are often called a “break glass” procedure. Because of the time it takes to get problematic code out of production, a run-time method to pull back features is sometimes necessary. This is where kill switches come in.
To implement Kill Switches, a good general practice is to wrap your flaky feature in an inverted feature flag. Your application should assume that the feature is working as expected so long as the feature flag is disabled. When you disable a flag by default, your application will still have the feature enabled. This is in case it can’t fetch the latest version of the feature flag. If you detect any problems with the integration, you can then easily turn on the kill switch. The feature will then turn off the feature flag.

The feature flag is disabled when everything is working as expected.
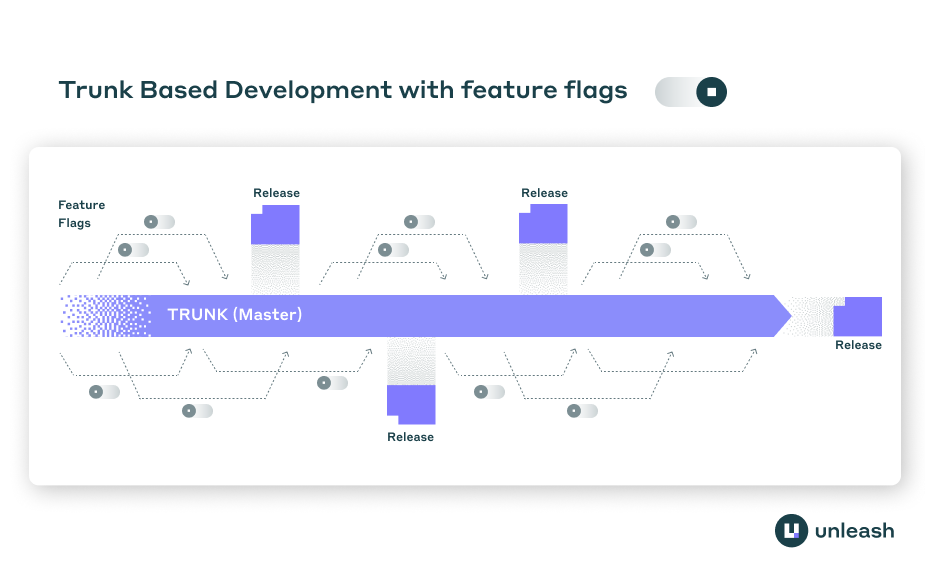
Trunk-based development
Trunk-based development is a software development strategy where all developers commit code changes to a single shared branch, known as the “trunk” or “mainline,” rather than working in separate branches for extended periods. This approach minimizes the complexity of merging code and aims to accelerate development by encouraging small, frequent commits to the main codebase.
Developers have shifted towards trunk-based development for several reasons, primarily driven by the need for faster, more efficient, and more reliable software delivery processes. It also helped that no one wants to spend the waning years of their life in a losing battle with git merge conflicts.
Feature flags can help by allowing teams to merge code for incomplete features into the trunk without exposing these features to all users. This way, you can continue developing and testing in production-like environments without affecting end-user experience.
Getting Started Using Feature Flags
Incorporating feature flags into your development and DevOps processes can significantly enhance your team’s ability to manage releases, test features, and respond to issues flexibly and efficiently. However, adopting feature flags often necessitates changes to your team’s workflows and a commitment to best practices to maximize their benefits while minimizing potential pitfalls.
11 Principles for Building and Scaling Feature Flags Systems
Before you can use feature flags, you need a feature flag system. There are many options on the market, including Unleash, but many large enterprises decide to build their own system. To help the community, Unleash has written about the 11 principles for building a large-scale feature flag system. These principles have their roots in distributed systems architecture and pay particular attention to security, privacy, and scale that is required by most enterprise systems. If you follow these principles, your feature flag system is less likely to break under load and will be easier to evolve and maintain.
Click on each link to learn more about each principle.
- Enable run-time control. Control flags dynamically, not using config files.
- Never expose PII. Follow the principle of least privilege.
- Evaluate flags as close to the user as possible. Reduce latency.
- Scale Horizontally. Decouple reading and writing flags.
- Limit payloads. Feature flag payload should be as small as possible.
- Design for failure. Favor availability over consistency.
- Make feature flags short-lived. Do not confuse flags with application configuration.
- Use unique names across all applications. Enforce naming conventions.
- Choose open by default. Democratize feature flag access.
- Do no harm. Prioritize consistent user experience.
- Enable traceability. Make it easy to understand flag evaluation
Develop Workflow and Rules of Use
Once you have a feature flag system, establishing a clear and coherent workflow for using feature flags is crucial. This workflow should encompass the entire lifecycle of a feature flag, from planning and implementation to monitoring and decommissioning. All team members should understand:
- How and when to implement feature flags: Establish criteria for deciding which features should be controlled by flags.
- Best practices for deployment: Integrate feature flags into your continuous integration and deployment pipelines.
- Monitoring and managing feature flags in production: Set up monitoring to track the impact of feature flags and ensure they are working as intended.
- Clean-up process: Define a protocol for removing flags once they are no longer needed to prevent clutter and maintain a clean codebase.
Develop Documentation
Comprehensive documentation is vital for ensuring that everyone understands each feature flag’s purpose and status. Documentation should include:
- Detailed descriptions: What each feature flag controls, why it was introduced, and how it works.
- Target user segments: Clearly define which users each flag affects and the rollout plan for different segments.
- Status tracking: Maintain a centralized repository or dashboard where stakeholders can see the current state of all feature flags and their impacts.
- Guidelines for use: Outline the processes for creating, deploying, and retiring feature flags, including who is responsible for each stage.
Additional Feature Flag Best Practices
- Testing: Regularly test feature flags in various environments to ensure they behave as expected and do not introduce unintended side effects. This is particularly true for kill switches which you need to be able to rely on in an emergency.
- Granular control: Design feature flags to control specific aspects of your application, allowing for more targeted and less risky changes.
- Auditing and accountability: Keep a log of changes to feature flags to track their history over time and ensure that modifications are traceable and justifiable. This includes who (Sally the developer) turned on what (new checkout flow) and for whom (all users in California).
- Feedback loops: Establish mechanisms for collecting feedback on the use of feature flags from both technical and business perspectives to refine your practices continually.
Best Practices When Using Feature Flags
There is a lot to say here about best practices when using feature flags. Read through the 11 principles for building a large-scale feature flag system mentioned above for a summary of some of the most important considerations. A few other best practices that spring to mind include:
Naming Conventions
It is crucial to adopt clear and consistent naming conventions for feature flags across all stakeholders. A well-chosen name provides immediate insight into the flag’s purpose, which is vital for understanding its role and impact at a glance.
- Descriptive names: Ensure the name of each feature flag clearly describes its function or the feature it controls. This clarity helps in recognizing the flag’s purpose across different teams and systems.
- Consistency: Apply a consistent naming pattern that includes the feature area and the specific aspect of the feature being toggled, aiding in quicker identification and management.
- Avoid ambiguity: Choose names that are specific enough to avoid confusion with similar features or flags.
All this is great, but…no one reads the docs! A great way to handle this is with code.
How to enforce naming conventions in feature flags
At Unleash, we build a feature flag naming pattern validator using JavaScript regular expression that is used before the flag can be created. Below is how we did it in case you want to build your own.
- The pattern is defined in the project settings and is enforced when creating a new feature flag.
- The pattern is also enforced when creating a new feature flag via the API.
- Patterns are implicitly anchored to the start and end of the string. This means that a pattern is matched against the entire new feature flag name, and not just any subset of it, as if the pattern was surrounded by ^ and $. In other words, the pattern [a-z]+ will be interpreted as ^[a-z]+$ and will match “somefeature”, but will not match “some.other.feature”.
- Feature flag naming patterns are defined on a per-project basis.
- In addition to the pattern itself, you can also define an example and a description of the pattern. If defined, both the example and the description will be shown to the user when they are creating a new feature flag.
The naming pattern consists of three parts:
- Pattern (required)
The regular expression that is used to validate the name of the feature flag. Must be a valid regular expression. Flags (such as case insensitivity) are not available.
- Example (optional)
An example of a name that is valid according to the provided pattern. Note: the example must be valid against the described pattern for it to be saved.
- Description (optional)
Any additional text that you would like to display to users to provide extra information. This can be anything that you think they would find useful and can be as long or short as you want.
For instance, you might define a pattern that requires all feature flags to follow a specific pattern, such as ^(red|blue|green|yellow)\.[a-z-]+\.[0-9]+$. You could then provide an example of a valid feature flag name (for instance “blue.water-gun.64”) and a description of what the pattern should reflect: “<team>.<feature>.<ticket>”.
Feature Flag Scope
Defining and adhering to the scope of each feature flag is essential to maintain clarity and prevent unintended consequences. Examples include:
- One flag per feature: Assign a distinct feature flag for each feature or behavior change to isolate its effects and simplify management and analysis.
- Well-defined boundaries: Clearly delineate what is and isn’t controlled by each flag to avoid overlap and ensure that each flag’s impact is predictable and isolated.
Grouping
Organizing feature flags into logical groups can streamline their management and improve the clarity of your feature flag ecosystem.
- Categorization: Group feature flags by their type (e.g., release, experiment, ops, permissioning) or by the application module they affect. This organization supports easier navigation and management, especially as the number of flags grows.
- Management tools: Utilize feature flag management platform like Unleash that support grouping or tagging to enhance organization and accessibility.
Clean Up
Have I said yet that feature flags are technical debt. Regularly reviewing and cleaning up old or obsolete feature flags is vital to prevent clutter, reduce technical debt, and maintain a healthy codebase.
- Regular audits: Incorporate feature flag reviews into your sprint retrospectives or regular maintenance cycles to identify and address no longer needed flags.
- Decommissioning process: Establish a clear process for safely removing flags once their associated features are stable and fully integrated or if the experiment or rollout is complete.
- Documentation: Track the lifecycle of each feature flag in your documentation, noting when and why it was removed to maintain a clear historical record.
Summary
This article discusses the benefits and best practices of using feature flags in software development. Feature flags are a powerful tool that allows developers to control the rollout of new features without redeploying the entire application. They lead to safer releases and faster development while simplifying life for developers. Want to try? Getting started for free using Unleash OSS.