What tools and processes are available for effective trunk-based development?

Michael Ferranti
VP of Strategy
May 19, 2026
The industry often treats trunk-based development as a cultural shift. Culture alone, though, won’t stop a bad commit from cascading through 100 microservices. Trunk-based development tends to break down when teams change their branching strategy without also upgrading the underlying infrastructure.
Safe merges depend on continuous integration and feature flags to decouple deployment from release. This guide covers the specific infrastructure, failure impact controls, and governance that make trunk-based development practical at enterprise scale.
TL;DR
- Trunk-based development requires continuous integration and automated testing to keep broken code from reaching production.
- Higher-performing teams keep three or fewer active branches and merge within a day.
- In enterprise monoliths, deployment orchestration helps manage the failure impact of single commits.
- High-velocity merging can create technical debt without systematic feature lifecycle management and flag retirement.
- Decoupling deployment from release lets teams enable gradual rollouts and instant disable switches without reverting commits.
The infrastructure prerequisites for trunk-based development
Continuous integration as the foundation
Trunk-based development is a required practice for continuous integration, according to DORA. The two concepts are inseparable. Continuous integration combines the practice of merging to a shared trunk with maintaining a suite of automated tests that run after every commit.
The goal is keeping the system in a working state at all times. Without the shared trunk, continuous integration does not exist. Teams working on isolated branches for weeks are not integrating continuously, regardless of how many automated tests they run locally. The integration phase still happens at the end of the cycle, recreating the bottlenecks continuous integration is supposed to solve.
The automated testing boundary
The case for trunk-based development is clear: it can eliminate merge conflicts and accelerate delivery. But the model depends on automated test coverage, which most organizations lack during initial adoption. Merging to the main branch daily without a continuous integration pipeline tends to ship broken code faster, not slower. The strategy relies on the test suite to catch regressions before they reach production. If the build takes thirty minutes to run, the rapid commit style becomes a bottleneck.
Decoupling deployment from release
McKinsey identifies trunk-based development as an essential enabler of true continuous delivery. It shifts the model from infrequent releases to low-risk increments. Decoupling deployment from release makes this possible. Feature flags act as the necessary guardrails. They let developers merge incomplete code into the main branch and deploy it to production without exposing the unfinished feature to end users. The code sits dormant in the production environment until the business decides to turn it on. Teams can learn more about the practices involved in continuous delivery to see how these components fit together.
Branching policy and the 24-hour rule
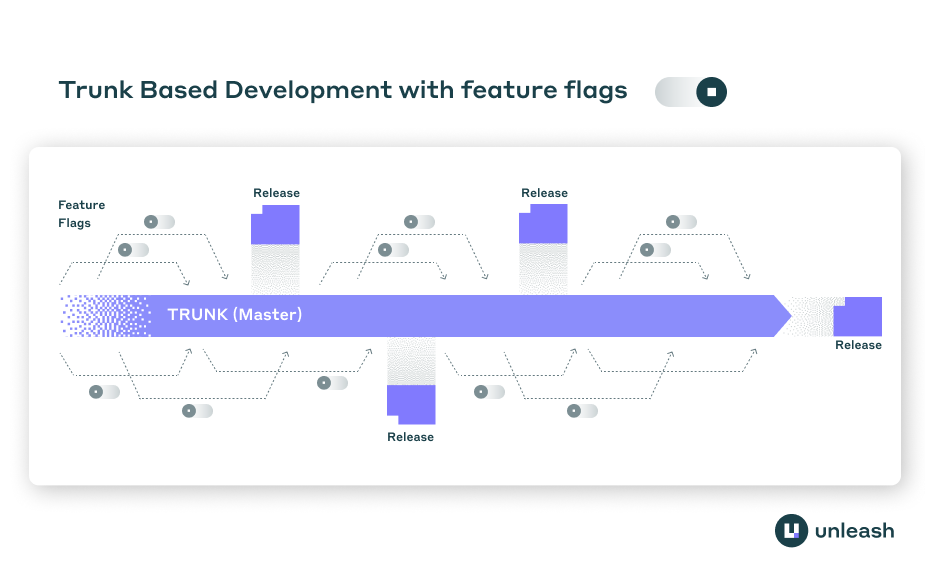
Once the infrastructure is in place, it changes how developers manage branches. The mechanics of short-lived branches dictate the daily developer workflow. DORA research shows that teams achieve higher software delivery and operational performance when they have three or fewer active branches in the application’s code repository.
These elite-performing teams merge branches to the trunk at least once a day. They avoid code freezes and integration phases. The trunk remains the single source of truth for the entire engineering organization. Every developer works from the same baseline, which means conflicts are resolved in minutes rather than days.
Enforcing the 24-hour limit
The 24-hour rule enforces this discipline. Branches should live no more than a day with active development. Ideally, a branch represents just a couple of hours’ worth of work. The 24-hour limit forces developers to break large features into atomic commits. A developer might build the database schema in one commit and the backend logic in the next.
When a developer finishes a unit of work, they merge it immediately. If the feature is incomplete, it stays hidden behind a feature flag. The main branch stays continuously releasable. Teams avoid the integration tax that accumulates when multiple developers touch the same code in feature branches over several weeks. The race to push code diminishes because the delta between the local branch and the trunk is always small. Setting these limits on branch lifetimes is the first step to implementing trunk-based development.
Scaling from small teams to enterprise monoliths
The failure impact problem
Small teams merge directly to the trunk with minimal friction. Enterprise environments face a different reality. At scale, a single bad commit can affect hundreds of interconnected systems. Uber found that 1.4 percent of commits to their monorepo affect more than 100 microservices. To manage this risk at scale, teams need deployment orchestration: systems that automatically monitor health signals across all dependent services during a rollout.
If error rates spike in a downstream service, the orchestration layer halts the deployment before the failure cascades. Monitoring these signals helps prevent one failure from breaking the entire fleet. In a monorepo, the impact area of a single developer expands quickly, which makes automated guardrails a practical requirement.
Mitigating monolithic rollback risks
The risk multiplies in monolithic architectures where boundaries are rigid. Reverting a bad commit in a monolith often forces the entire team to roll back their changes. A rollback disrupts everyone’s local environment and can halt the delivery pipeline. When that’s the safety net, developers tend to hoard code in local branches, which works against the purpose of the shared trunk.
Tink, an open banking platform owned by Visa, addressed this monolithic rollback risk using Unleash. The engineering team uses feature flags to decouple rollouts across 25 distinct services and environments. When a new feature causes an issue, they toggle it off — sub-second with Unleash Enterprise Edge streaming, or on the next SDK refresh (7-8 seconds by default) otherwise.
There’s no need to revert the deployment or coordinate a rollback across the monolith. The main branch moves forward, and the problematic code stays dormant until the team pushes a fix. Runtime control replaces the need for emergency hotfixes and cherry-picking operations. Developers merge code with confidence, knowing the deployment mechanism is separated from the release mechanism.
Governance for the cautious
The documentation multiplier
High-velocity merging can create technical debt if left unmanaged. The pressure of maintaining an always-releasable trunk benefits from firm guardrails. The 2023 DORA report found that trunk-based development has 12.8 times more impact on organizational performance when high-quality documentation is in place. Without clear guidelines, the rapid commit style can contribute to developer burnout and system instability. Teams need documented standards for how to wrap code in flags, how to name those flags, and when to remove them. Without these standards, the codebase can quickly accumulate abandoned experiments.
Feature lifecycle management
The advantages of adopting feature flags far outweigh the downsides, but some of the complexity of trunk-based development does migrate from the version control system into the application code. Developers use feature flags to isolate work in progress, and over time, those flags accumulate. When left unmanaged, stale flags create a hidden tax that increases the number of execution paths the team must test and maintain.
A codebase with hundreds of dormant flags becomes difficult to reason about, so organizations need governance to control this accumulation. Feature lifecycle management provides end-to-end control over how features are released. It helps ensure every feature is intentional and supported by a clear path to flag retirement. Teams use release templates to standardize workflows and rely on native notifications to identify stale flags.
By providing visibility into the feature flag lifecycle, Unleash generates a list of stale flags ready for removal. Developers can then take that list and prompt the Unleash MCP server to clean up the corresponding code once a feature reaches 100 percent exposure. Systematic cleanup keeps flag sprawl from degrading the codebase and keeps the trunk clean for future development. Managing technical debt with feature flags helps sustain high deployment frequencies.
Progressive delivery patterns
Once feature flags are properly governed and technical debt is managed, teams can use those flags for advanced progressive delivery patterns. When the trunk is always releasable, teams can implement progressive delivery to control exactly who sees what, and when. These patterns rely on runtime control, not deployment pipelines. They shift the responsibility of feature exposure from the deployment system to the application logic.
- Targeted exposure: Teams expose new code to specific cohorts, such as internal users or beta testers, before a general release. Product managers gather feedback without risking the broader user base.
- Percentage rollouts: Organizations gradually increase traffic to a new feature. They monitor system health at 1 percent, 10 percent, and 50 percent intervals. If error rates spike, the rollout halts.
- Instant disable switches: Engineers disable problematic features without redeploying or reverting commits — sub-second with Unleash Enterprise Edge streaming, or on the next SDK refresh otherwise. Mean time to recovery drops from minutes to moments.
- Testing in production: Quality assurance teams validate features with real data behind a flag. This eliminates the need for a separate testing phase that lags a sprint behind development.
Wayfair demonstrates the impact of these patterns at scale. The e-commerce platform handles over 20,000 requests per second during peak usage. By adopting Unleash for feature management, Wayfair increased deployment frequency and significantly reduced the engineering hours previously spent on manual testing and certification bottlenecks. The platform handles the scale natively. Developers merge code rapidly while maintaining tight control over the user experience. The transition from a homegrown system to an enterprise platform eliminated the maintenance overhead that previously slowed their delivery cycles.
Culture follows infrastructure
The industry frames the move away from GitFlow as a cultural challenge, but culture follows infrastructure. Developers tend to resist trunk-based development when they feel unsafe committing directly to the main branch. Once the three-legged stool of continuous integration, automated testing, and feature flags is in place, the cultural shift becomes much easier.
To eliminate merge conflicts and accelerate delivery, teams can build the testing infrastructure and implement runtime controls before changing their branching policy. Organizations can explore specific trunk-based development use cases to see how these infrastructure changes support different organizational needs.
FAQs about trunk-based development
How do I handle database migrations in trunk-based development?
Database changes typically use an expand-and-contract pattern to maintain a releasable trunk. You first deploy a migration that adds the new schema while keeping the old one active, then update the code to write to both. Once the data is synchronized, you toggle the read path to the new schema using a feature flag before finally removing the old columns.
How long should short-lived feature branches stay open?
Branches should live no more than 24 hours to avoid the integration tax of long-lived code. Ideally, a branch represents a couple of hours of work and is merged as soon as the unit of work passes automated tests. According to DORA research, elite performers keep three or fewer active branches to minimize divergence.
What happens when a bad commit reaches the main branch?
In a trunk-based model, a bad commit affects the entire team immediately, which makes rapid recovery essential. Rather than reverting the commit and disrupting everyone’s local environment, teams can use feature flags as a kill switch to disable the problematic code path. This lets the trunk move forward while the team pushes a fix.
How do I manage pull requests without slowing down merges?
To maintain high velocity, teams replace long asynchronous reviews with synchronous practices like pair programming or small, atomic pull requests. When a pull request represents only a few hours of work, reviewers can approve changes in minutes. High-performing teams often automate the final merge using a merge queue to prevent race conditions at scale.
What is the cost of maintaining homegrown feature flags?
Maintaining an internal flag system often creates significant overhead as teams scale. For example, Wayfair found that their homegrown solution cost approximately three times more to maintain than a dedicated platform. Beyond direct costs, internal tools often lack the security, audit logs, and stale flag detection required for enterprise governance.
Share this article